
This story started some time ago with intention to learn a bit about buzz words and their influence to modern word. On other hand all of the applications working for a while on Docker, and from this side come another problem. With growing up container infrastructure at home lab appeared problem with resources and upsetting performance of Hyper-V VM (yes, it still exist).
Prologue
To relief the pain of resource clash we come to the decision point – what should be used: Docker swarm or Kubernetes, if then Kubernetes native or different forks of it? First iteration was performed around 2-nodes canonical k8s cluster. Everything was fine, but before the upgrade, and this story is starting here. As a container runtime for a while have been used docker but with modern winds of change lab was switched to containerd.
Successful upgrade lead whole test infrastructure to non-functional state with some sparks of connectivity between nodes. All attempts to reanimate cluster bring some understanding of troubleshooting but DevOps approach to rebuild and recreate seems much more attractive.
Brand new 3 node cluster with containerd onboard was almost ready to take-off, but, as usual in this story, something goes wrong, and it was network.
Initial network should looks like this:
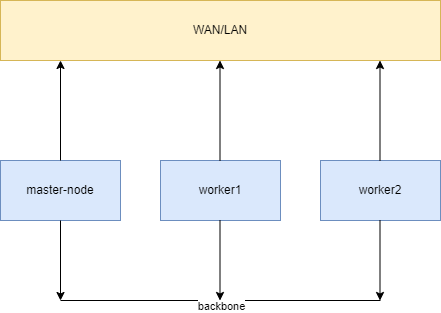
As a network plugin, by initially unknown reason, I started with calico. The good in calico – is multiple options to setup and adjust. The bad one – unfortunately it’s really tricky and complicated to setup properly sometimes, and as a result – I get some very strange issues in the very beginning. Troubleshooting gives nothing and, despite the separate cluster network, calico pods constantly getting network disruption on worker nodes, as well as permanent ContainerCreating for CoreDNS and CrashLookBackOff for calico pods. calicoctl node status also didn’t help with investigation. So, cluster exist, but not properly, and even not fit for lab purpose. For those curious who what to shed the light on this issue, take a look on github, unfortunately Autodetection as well as other tricks doesn’t work.
For educational purpose below you can find some work notes during this exercise:
One thing, that, probably worth mention in all of this things:
kubeadm init --pod-network-cidr=172.16.0.0/16Funny part that I come across – is network issues with really huge default pod-network-cidr. In first iteration of installation I caught error with overlapping address range, so, it’s really important to keep it in mind.
ifconfig eth1 10.200.0.1 netmask 255.255.255.0 upIfconfig was used here to setup internal cluster networking. Nit highly, but recommended to use in anything, that might be more or less productionised.
The only thing left it was issues with Hyper-V and, probably, with canonical Kubernetes itself, that’s why, further waste of time and move with more engineering approach – use something, that will work.
k3s.
k3s come as a good alternative option – it is still seeming quite robust, used in many homelab projects and reminds k8s in everything. Simplified installation, that could be customized and a documentation, that seems much more readable force me to give a shot to k3s.
As you can notice in previous snippet – meanwhile networking slightly changed during experiments.
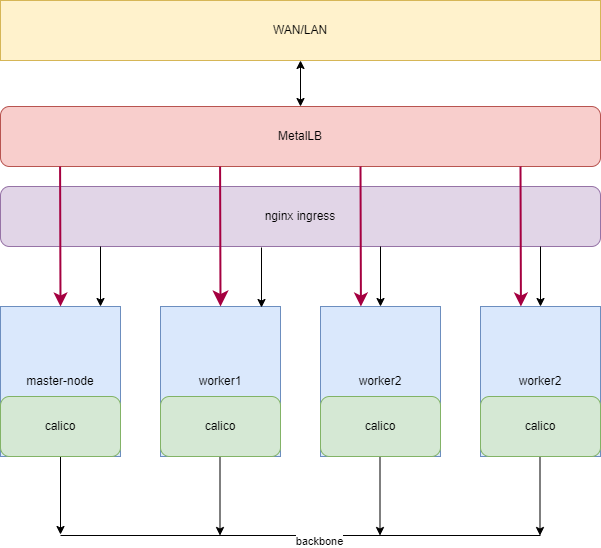
Main point of usage of the LoadBalancer with the Ingress Controller is to get both of two worlds: with load balancer you would be able to control some services through dedicated IP addresses and Ingress will help to publish other services with the DNS names.
Initial idea was to use LB for dedicated services such as GitLab, blog, etc and Ingress – for bunches of services such as radarr, sonarr and other -arr containers. Still think that it will work, except some services, that really refuse to use ingress, i.e., Qbittorrent.
Storage
SMB
For historical reasons of the infrastructure, as well as heavily-heterogenous environment, starting point for kubernetes storage was SMB. Almost everything in existing environment stored on windows share and all of the operations also working only with CIFS. So, to make it work, just a few actions is really required:
Few more notes about nobrl – this is something that require to use SQLite DB on remote SMB share, by strange reason without it. For most curious – feel free to read here:
Do not send byte range lock requests to the server. This is necessary for certain applications that break with cifs style mandatory byte range locks (and most cifs servers do not yet support requesting advisory byte range locks).
nobrl
In general – this is most non-problematic part, that was so far.
Rook
But, unfortunately, no everything could be deployed on the remote storage, and SMB speed for the most application is pathetic. So, in this case we need to deploy some software-defined storage, as we don’t, actually, want to store something needful for our apps without additional copies on the local storage. So, in this case we need to find something not cloud ready, but very specific for on-prem deployments. And here we could find just a few options, and only two of them seems to be working: Rook and Longhorn. In dark memories of Windows Longhorn I prefer to go with the first one.
For those, who read carefully, could note, that, eventually, appeared 4th node in cluster. It’s kind of inconsistency on one hand, and best practices from the Rook side on another:
Cluster settings for a production cluster running on bare metal. Requires at least three worker nodes.
Rook
And this the answer for the mysterious node appearance. Definitely, cluster could be deployed with less storage instances, but, why not?
So, installation is quite easy, if everything goes well. If not – read “If everything goes wrong section”
Some notes about Rook: it works and works quite well, but storage consumption is point to discuss. Unfortunately, I come across issue related with unexpectedly big storage usage. In terms of reinitiating of storage it might be a bit tricky as require disk cleanup with
blkdiscard $DISKBut, I hope in your experiments you will be more cautions and will keep eye on available diskspace.
Operate
Measurement of our success will be ability to use our cluster, deploy something and so on. Actually, here few hints, that could be useful in your k8s-journey:
But, kubernetes one will be definitely more useful.
On this happy note we will finish today story about initial k8s cluster setup. Hope it wasn’t so boring and we will continue with next part about application deployment.
I really understand there is a bunch of equal articles with approximately the same content, but this one inspirited with sour experience and number of try and fails on the way to the same results. And most of those articles were useless because their primary target is to deploy in predictive and vendor managed clouds, and this is not applies to the homelabs.
But let’s recap what do we able to do:
- Install k3s
- Setup network
- Setup Ingress, LoadBalancer
- Setup storage
But still you will be able to take a look on the articles
- https://www.mirantis.com/blog/how-install-kubernetes-kubeadm – some general guide
- https://www.nocentino.com/posts/2021-12-27-installing-and-configuring-containerd-as-a-kubernetes-container-runtime – containerd setup
- https://github.com/containerd/containerd/blob/main/docs/getting-started.md – another containerd installation
- https://rook.io/docs/rook/v1.10/Getting-Started/quickstart/#create-a-ceph-cluster – Rook setup
- https://github.com/kubernetes-csi/csi-driver-smb – SMB driver and quickstart